Life on the edgeThe era of the cloud’s total dominance is drawing to a close
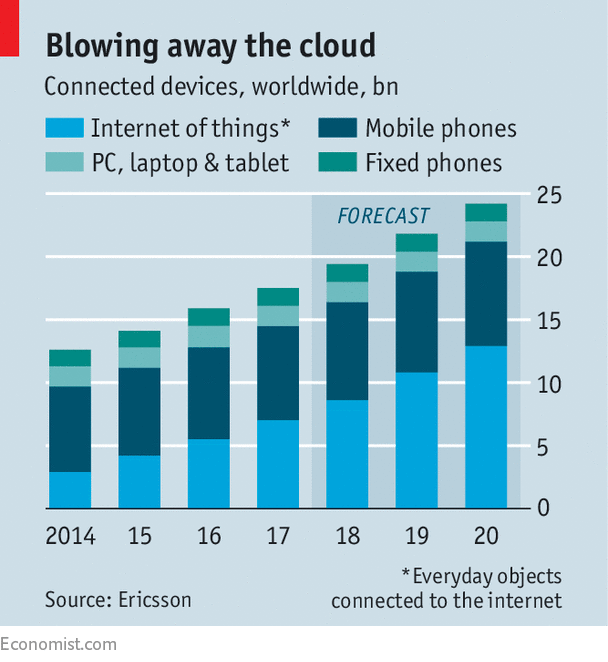
The rise of the “internet of things” is one reason why computing is emerging from the centralised cloud and moving to an “edge” of networks and intelligent devices

CONNECTED devices now regularly double as digital hoovers: equipped with a clutch of sensors, they suck in all kinds of information and send it to their maker for analysis. Not so the wireless earbuds developed by Bragi, a startup from Munich. They keep most of what they collect, such as the wearers’ vital signs, and crunch the data locally. “The devices are getting smarter as they are used,” says Nikolaj Hviid, its chief executive.
Bragi’s earplugs are at the forefront of a big shift in the tech industry. In recent years ever more computing has been pushed into the “cloud”, meaning networks of big data centres. But the pendulum has already started to swing: computing is moving back to the “edge” of local networks and intelligent devices.
Latest updates
-
The wait continues for a new male grand-slam champion in tennis
-
America’s opioid epidemic is driven by supply
-
How to board a plane without a boarding pass
-
In “Phantom Thread”, Paul Thomas Anderson weaves a masterpiece
-
How feats of endurance cement social bonds
-
Why Turkey’s troops are in Syria again
As with the rise of the cloud in the early 2010s, the shift will cause upheaval. Many startups will try to ride the trend, as will incumbents such as hardware makers. But the real fight will be over who colonises the edge and, in particular, which firms will control the “internet of things” (IoT), as connected devices are collectively called. Will Amazon Web Services (AWS), Microsoft and other large cloud providers manage to extend their reach? Or will the edge be the remit of a different set of firms, including makers of factory equipment and other sorts of gear?
Since emerging in the 1950s, commercial computing has oscillated between being more centralised and more distributed. Until the 1970s it was confined to mainframes. When smaller machines emerged in the 1980s and 1990s, it became more spread out: applications were accessed by personal computers, but lived in souped-up PCs in corporate data centres (something called a “client-server” system). With the rise of the cloud in the 2000s, things became more centralised again. Each era saw a new group of firms rise to the top, with one leading the pack: IBM in mainframes, Microsoft in personal computers and AWS in cloud computing.
Better technology is one reason why computing is again becoming more distributed. Devices at the edge, from smartphones to machinery on the shop floor, are becoming more intelligent. Equipped with powerful processors, they can now tackle computing problems that a few years ago needed a fully loaded server. As for software, its increased flexibility means it can function well on the edge. Many applications are now “virtualised”, meaning they exist separately from any specific type of hardware: code can thus be packaged in digital “containers” and easily moved around within data centres—and, increasingly, closer to the edge.
Demand for computing at the edge is growing, too, often for non-technical reasons. Many countries have laws that require data to stay within their borders or even within the walls of a company. Firms want to use data but, worrying about leaks, often prefer to keep their own information inhouse. Consumers, for their part, care about privacy, which Bragi hopes to address with its self-sufficient earplugs.
The dominant narrative in the tech industry—that most data are best crunched centrally in the cloud—is also undermined by the fact that many new applications have to act fast. According to some estimates, self-driving cars generate as much as 25 gigabytes per hour, nearly 30 times more than a high-definition video stream. Before so many data are uploaded, and driving instructions sent back, the vehicle may well already have hit that pedestrian suddenly crossing the street.
Changing economics are another consideration. The faster adjustments can be made—for instance, to optimise the operations of a machine in a factory—the bigger revenue gains tend to be. That means data are often best analysed as they are captured, which needs to be done locally. The costs of transferring, storing and processing data in the cloud can be avoided too.
Car-boot brains
These constraints explain why services using artificial intelligence (AI) are increasingly split in two, much like client-server applications, explains Pierre Ferragu of Bernstein Research. The algorithms of autonomous cars, for instance, are first trained in the cloud with millions of miles of recorded driving data; only then are they deployed on powerful computers in the boot, where they steer the car by interpreting live data. Similarly, many video cameras used for surveillance now ship with face-recognition software trained in the cloud, as does Apple’s latest iPhone model. In November, Google announced an addition to TensorFlow, its AI technology, which allows developers to deploy algorithms to mobile devices.
But in many cases even the training of algorithms must happen locally for AI applications to make commercial sense, argues Simon Crosby, chief technology officer of Swim, a startup. For instance, sending the four terabytes of data generated daily by traffic lights at intersections in Palo Alto, in Silicon Valley, to a cloud provider for processing would cost thousands of dollars a month. Swim has built a system that does the equivalent job for few hundred dollars by learning from the data on the fly as they are generated.
Although a shift to the edge is now generally acknowledged to be under way, opinions are divided over how it will change the technology industry. Nobody expects the “end of cloud computing”, to quote the provocative title of a podcast by Peter Levine of Andreessen Horowitz, a leading Silicon Valley venture-capital firm. He himself predicts that centralised clouds, in particular those of Amazon, Google and Microsoft, will continue to grow.
But smaller and more local data centres are springing up everywhere. Firms such as EdgeConneX and vXchnge have built networks of urban data centres. Vapor IO, a startup, has developed a data centre in a box that looks like a round fridge and can be quickly put in any basement. Makers of telecoms equipment, including Ericsson and Nokia, as well as network operators, talk a lot about “mobile edge computing”, which amounts to putting computers next to wireless base stations or in central switching offices. Some also speculate that one reason why Amazon last year bought Whole Foods, a chain of grocery shops, for nearly $14bn, was to accumulate property for local data centres.
Computer makers see the shift as a chance to regain lost territory. Dell EMC and HP both want to sell more gear to firms keen to crunch data locally. But they are limited in how far they can move to the edge, says George Gilbert of Wikibon, a consultancy. These firms know how to sell commodity hardware to IT departments, but most IoT gear will be more customised, requires special software and is sold to people managing machinery. Cisco, which sells all kinds of internet equipment, seems well placed.
Big cloud-computing providers are also trying to colonise the periphery. In May Microsoft changed its slogan from “mobile first, cloud first” to “intelligent cloud and intelligent edge”. It sells services that dispatch software containers with AI algorithms to any device. AWS’s portfolio now includes a service called Greengrass, which turns clusters of IoT devices into mini-clouds. In buying the Weather Company for $2bn in 2015, IBM wanted weather data, but also thousands of “points of presence” for edge computing.
Whoever prevails, computing will become an increasingly movable feast, bits of which can be found in even the smallest devices. Processing will occur wherever it is best placed for any given application. Data experts have already started using another term: “fog computing”. But the metaphor is a bit, well, foggy. Better, and more poetic, would be “air computing”: it is everywhere and gives things life.
